
Introduction
Malicious emails have been widely used by cybercriminals to attack numerous victims using techniques such as fraud, phishing and malware attachments. While existing solutions can detect malicious attachment files or phishing URLs in emails, it is a challenging problem to identify hand-crafted social engineering emails that often don’t contain any malicious payloads. We introduce our Natural Language Processing (NLP) approach to recognise malicious intent in email text using BERT (Devlin et al., 2018). BERT is a Transformer based NLP model that has achieved great success in NLP tasks including sentiment classification, machine reading comprehension, and natural language inference. However, operating complex BERT models remain challenging in real-time security systems.
In this post, we’ll describe BERT and DistilBERT which is a leaner BERT model, and then present our fine-tuning approach, Context-Aware Tiny BERT (CATBERT) that compressed the DistilBERT model to produce a high-performing model for malicious email detection, giving us almost two times the throughput. Our Context-Aware architecture with the content features from email text and the context features from header fields improved the model’s detection performance.
BERT
BERT is Google’s Transformer based model which has achieved state-of-the-art results in 11 NLP tasks as of 2018. Its training procedure consists of two stages. In the first pre-training stage, a BERT model is trained to predict masked words in a sentence with large-scale datasets. In the second stage, the pre-trained model is fine-tuned with a labelled target dataset for a specific task. For the fine-tuning step, a classification header is added and the whole network is jointly optimized with supervision. Since the model’s parameters are initialized in the first stage with large-scale data, fine-tuning just requires training for two or three epochs to yield state-of-the-art performance.
Model Compression
While complex BERT models obtain impressive results, the full-sized models are computationally expensive and memory intensive. Model compression methods have been introduced to solve the issues with large models by reducing the parameters of models without significantly decreasing the model performance. Parameter pruning and knowledge distillation are efficient approaches for compression. Pruning methods remove less important neurons or collections by measuring the importance of neurons. While these approaches result in a smaller sparse network, the speedup of inference time is not guaranteed as many deep learning frameworks do not fully support sparse operations. Knowledge distillation compresses deep networks into shallower ones where a compressed model, a student network, mimics the function learned by a complex model, a teacher network. One of the advantages of knowledge distillation is that any student architecture can be trained with a complex teacher network. The method trains a student model with a classification loss and a distillation loss. The distillation loss indicates the output differences between the two models and minimizing both losses in training allows the student to learn rich representations from the large teacher. DistilBERT obtained comparable performance to BERT using knowledge distillation and reduced the number of Transformer blocks from 6 in BERT base model to 3.
Email Model
Our CATBERT model utilizes a pre-trained DistilBERT model (Sanh et al., 2019) which applies knowledge distillation with BERT. A student network, DistilBERT was trained with a large teacher network, BERT in pre-training. Since the core components in BERT were highly optimized, our focus was to compress DistilBERT by reducing the number of Transformer layers.
Architecture
DistilBERT has the same general architecture as BERT. The token-type embeddings in BERT are removed and the number of layers is reduced by a factor of 2. As shown in Figure 1, Our email model further compressed DistilBERT by a factor of 2 and obtained comparable performance. As DistilBERT model was pre-trained with a large teacher using large-scale datasets, we reuse the optimized parameters by initializing our smaller CATBERT model from the DistilBERT by taking one Transformer layer out of two. We denote DistilBERT6 as the original DistilBERT and DistilBERT3 as our smaller version which contains 3 Transformer layers.

As shown in the Figure 2, CATBERT model has a series of three classification layers on top of the three Transformer layers. The Transformer layers process the content features from the emails, and then the classification layers receive this these processed content features the Transformer layers as well as contextual information extracted from email data. For the content features, the email’s text data is encoded as a single sentence in BERT and BERT tokens are fed into the embedding layer. Context features are directly fed into the classification layer and concatenated with the content representations obtained from the CLS token representation in the last Transformer layer (see below), then fed into the final classification layers. The final Sigmoid unit returns predictions learned using both inputs.
The resulting model is significantly smaller than the DistilBERT model. We attempted to compress it further by using knowledge distillation to fine-tune CATBERT with a large BERT teacher, unfortunately this did not yield any significant improvement.
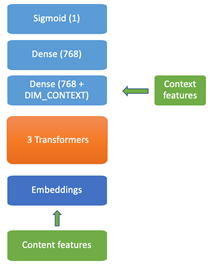
Input Representation
Email messages consist of subject and body, which our model uses by concatenating the text from subject and body into a single “sentence”. The text in the email body often contains HTML tags, which we remove using simple regular expressions. This pre-processed text is then tokenized by BERT’s sub-word tokenizer, and the extracted tokens are fed into the model as content features. The output from the Transformer portion of the model for the first CLS token is then combined with context features to do the final representation.

Token inputs are represented as token embeddings and the position values of tokens are represented as positional embeddings. As shown in Figure 4, there are two special tokens, CLS is the first token for every input and SEP is added as the last token. The hidden state for CLS token is fed to a target-specific classification layer. The two embeddings are jointly learned during training and summed vectors are used as input to Transformer layers.

We also extract generic header features to provide additional information, as noted above. The header features include a number of hand-crafted features that capture the context information between senders and recipients, such as whether or not the communication is an internal email within a same organization, or the number of recipients.
Performance
We collected a dataset of over four million of emails and meta data from a threat intelligence feed and our email system at Sophos. By splitting samples with timestamp, 70% of samples were used for training and 30% of samples were used for validation.
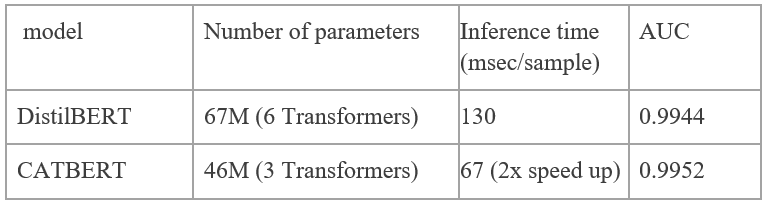
Table 1 shows the performance, model size and inference speed of DistilBERT and CATBERT models. Two models use the same core BERT architecture, but they vary in the number of Transformer layers. The DistilBERT has 6 and the CATBERT has 3 Transformer layers. While the number of parameters of CATBERT has 30% smaller than DistilBERT, the smaller model achieves improved AUC performance with content and context information. The inference time column in the table 1 shows the prediction speed on a single CPU per sample and CATBERT improves the inference speed by 2x against DistilBERT.
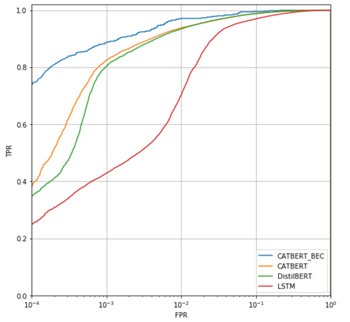
CATBERT model was able to pick up on subtleties of email topic, tone and style, which accurately detected new, targeted phishing attacks. The Figure 5 compares the ROC curves of models. Our malicious samples include phishing and a small number of BEC (Business Email Compromise) samples which are targeted social engineering attacks. CATBERT achieved an 82% and 90% detection rate on phishing and BEC attacks respectively at a 0.1% false positive rate.
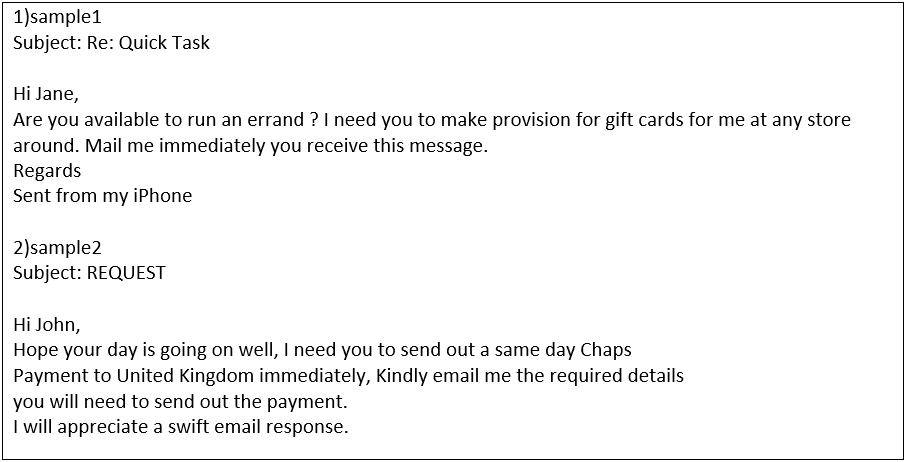
The following BEC emails are hand-crafted social engineering attacks and our email model detected them.
Interpretability with LIME
We use LIME approach to examine our model’s interpretability. LIME explains models by learning an interpretable model locally around the prediction. While BERT models are complex, making it hard to understand the reasons behind certain predictions, LIME learns a linear regression model within a local neighborhood about the test point, and provides the learned weights. Because this local model is linear, the weights can be directly interpreted as estimates in the change in prediction probabilities caused by the token in question for that specific sample. For example, In Figure 6, orange indicates malicious items, while blue color indicates benign ones. The word “payment” has the highest weight and is highlighted in the email text.
Conclusion
In this blog post, we introduced our approach to detecting malicious emails using a bleeding-edge NLP model, BERT. While mass phishing campaigns can be detected using traditional signature and ML technologies, hand-crafted spear-phishing emails pose a greater threat because they may not share word sequences or word choices with previously seen attacks. Despite the additional challenges of such attacks, our solution detected them with a high degree of accuracy while also being 30% smaller and 2 times faster than the already highly-optimized DistilBERT, which itself is already 40% smaller than vanilla BERT.