Introduction
The machine learning-based detection technologies we build at Sophos AI rely on many information sources, including binary programs, system behaviors, URLs, and web content. In this blog post, we discuss research towards augmenting this detection toolset with a model that takes IP addresses as its information source (and associated metadata, such as the ISP and geolocation data associated with an IP address). We show that because malicious IP addresses tend to “cluster together”, as do benign IP addresses, we can do a reasonable job of predicting whether or not a previously unseen IP address will behave maliciously. In mathematical modeling parlance, this suggests we can get a good signal from IP addresses, and use IP address information to increase the accuracy of Sophos’ many-layered approach to attack detection.
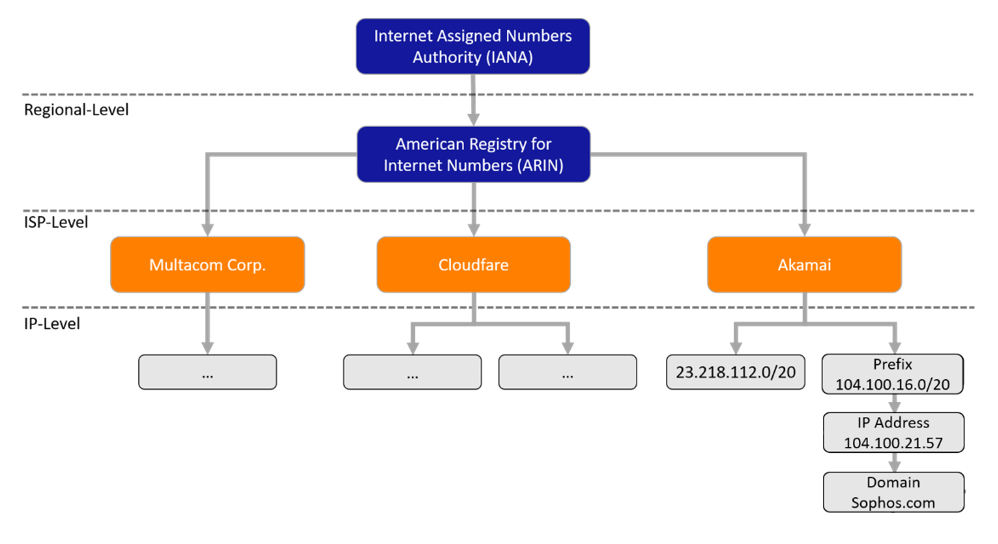
Let’s begin by developing some intuitions about why IP address information may be a useful signal in cyber attack detection. If we look at Figure 1, we can see a schematic of the hierarchical structure of the internet IP address space. We can trace an IP address from a specific address to a CIDR block IP-range, to an ISP, to a registry. For example, when we look up sophos.com, it resolves to the IP address 104.100.21.57, which is served by Akamai. The Akamai Internet Service Provider (ISP) owns various, non-contiguous IP prefixes, one of which is 104.100.16.0/20 where the IP address hosting sophos.com belongs. ISPs are further grouped into regional registries, all under the Internet Assigned Numbers Authority (IANA).
Internet hierarchy
The fact that the IP address space is organized in this way suggests that it has a semantic structure that a machine learning approach could make use of to predict IP maliciousness. But this begs the question: in this hierarchical structure, are the threats distributed evenly across various IPs? At what level does the variation take place? At the level of ISP? Of regional registry? The answers to these questions bear on how we should approach detecting malicious IP addresses. We gathered data from various sources, to gain insight.
Specifically, we collected IP addresses and domains from Sophos customer telemetry that span over half a year starting form January 1, 2020, which we further resolved to IP addresses, and labeled on the basis of our internal tools and telemetry (see below) obtaining 455248 labeled IP addresses. We split the dataset based on when we first “saw” IP addresses in the data, setting aside 2 months of data as a test set to form an 80 / 20 split in terms of size.
The malicious part in the telemetry is a combination of IPs involved in various malicious activities such as malware repositories hosting malicious content, representing a significant security concern, phishing sites and telephone scams, service theft advice sites, and “callhomes” addresses which are to be used for command and control servers (C2) by malware running on infected computers. As benign data we selected IPs hosting social network infrastructures, search engines, online stores, video hosting providers, and so on. The dataset contains 160813 malicious IPs and 294435 benign. We threw away addresses serving mixed content.
To extend our view on IP addresses associated with email campaigns, we down-sampled the combination of the Spamhaus and DNSWL email reputation datasets to match the magnitude of the web based dataset, resulting in 432792 labeled IP addresses, with 215909 malicious and 216883 benign IPs.
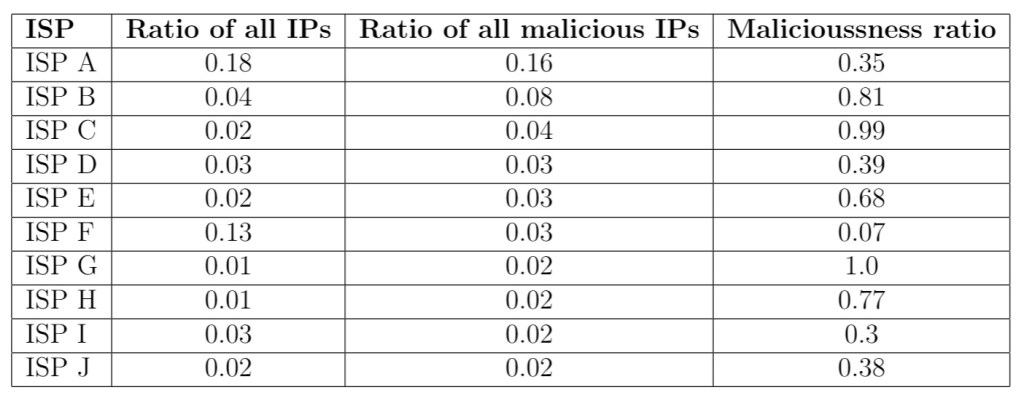
Some providers might go to great pains to maintain a high reputation for their infrastructure, and be quick to act on reports of malicious behaviours. Other (so-called “bulletproof”) providers might exclusively host malicious content. Looking at Table 1, we can see that some ISPs have contributions to the malicious landscape – at least in our telemetry – that are disproportionate to the size of the IP space they own. For example ‘ISP C’ hosts 2% of all IPs in our telemetry, but it contributes 4% of volume to malicious part of the telemetry, and all we can observe from that ISP is almost exclusively malicious.
Top 10 ISPs in the dataset
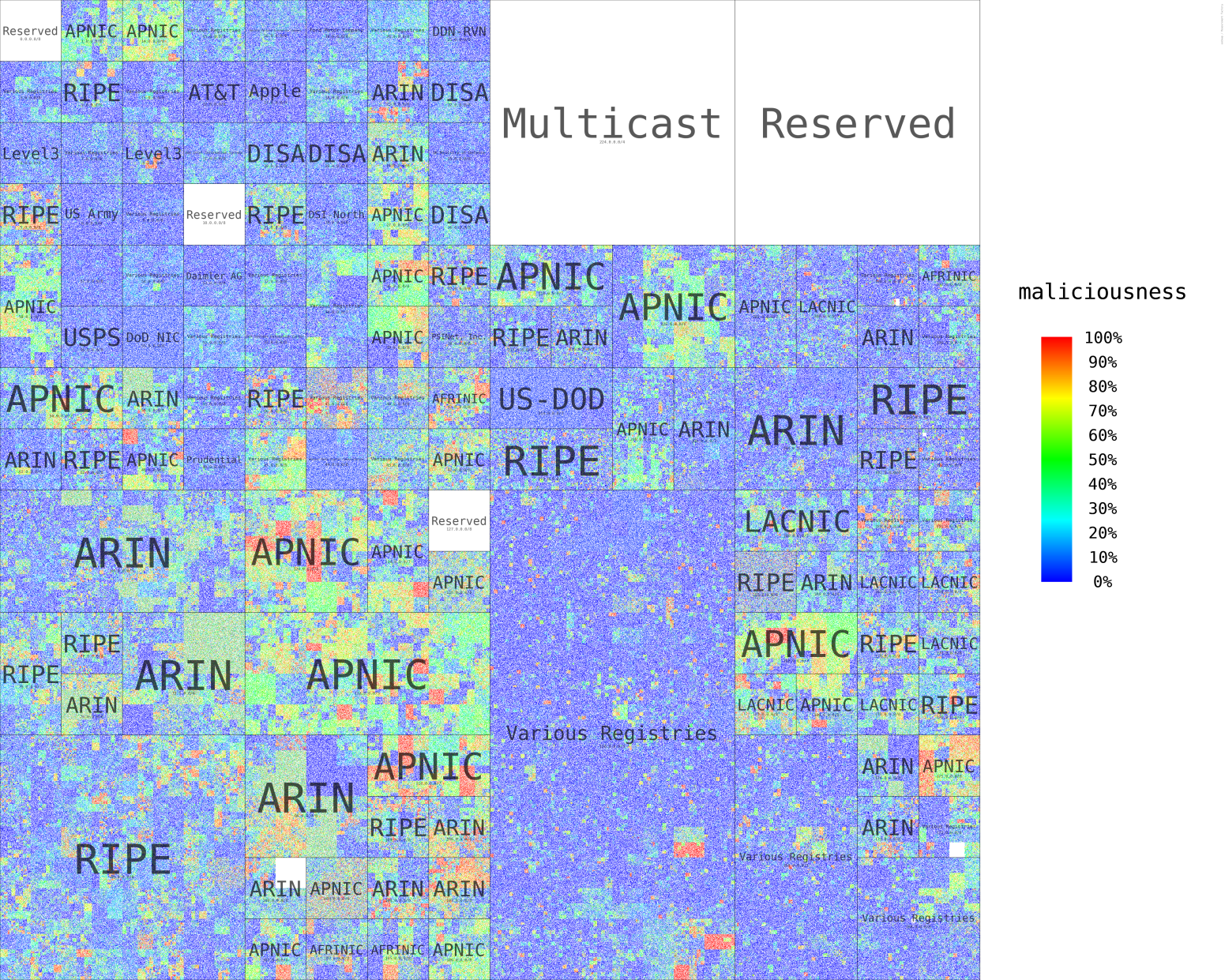
We can use Hilbert curves to visualize malicious and benign IP space, gaining some intuition around how they’re distributed. A Hilbert curve is a mathematical structure that places IP addresses that are close together in the address space close together in a 2-dimensional plot. This produces a nice, compact output that lets us examine IP space: CIDR (Classless Inter-Domain Routing) blocks are represented as contiguous rectangles. In the Hilbert curve plot below, the blue points represent training data IP addresses that are benign, and the red points malicious ones. We can easily observe clustered blocks on the curves that seem to be overwhelmingly malicious.

Hilbert curves
Machine learning model prototypes
Now that we have a confirmation the IP space is skewed in terms of “bad neighborhoods” that tend to harbor malicious activities, we can start building machine learning classifiers that can model the structural bias. We set out to build models that have IP addresses as their core input. IPs can be represented in multiple different forms. For example, take Google’s nameserver: we have the following ways of representing an IP address:
- 162.76.207.51 – standard decimal dotted
- 2722942771 – integer
- 10100010.01001100.11001111.00110011 – binary
Convolutional subnet representation
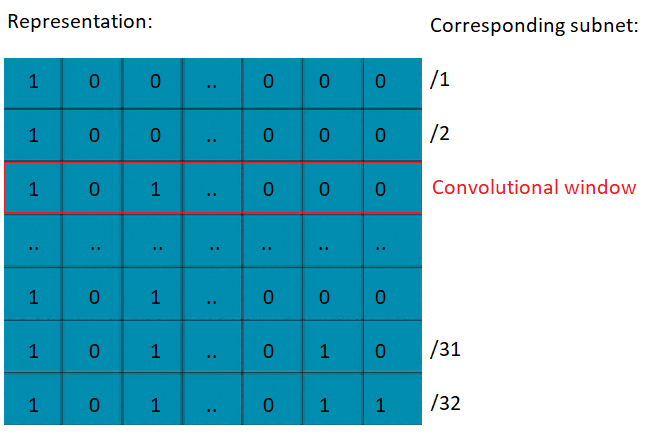
Our first approach builds upon the binary representation. We can convert an IP address to a matrix of all of its subnets, with one row corresponding to a single masked subnet, where in the ith row we zero out the last i bits of the full binary IP address. For example, in figure 3, row 32 of the matrix contains the /32 the IP address itself, and the 24th row would contains the /24 subnet of the IP address.
This representation works well with convolutional neural networks (CNNs). In a convolutional neural network, we take a matrix as an input, assign importance to its various aspects/features by sliding a convolutional window across it.
The general idea is that this lets the model handle the subnets at sufficient level of granularity. We use a 1-dimensional convolution with shape (1,32) and stride (1,1) across the generated matrix.
The IP address classification problem can be also phrased as a sequence classification task. Transformers are used to handle sequential data with complex dependencies, such as natural language using a self-attention mechanism to attribute importance to the words in the source text. Our analogous idea is to train the Transformer model to pay attention to important parts of the IP address, which correspond to the respective subnets. As our second proposal we fine tuned a pretrained DistilBERT model from Hugging Face on our dataset, which is one of the smaller models of the BERT family.
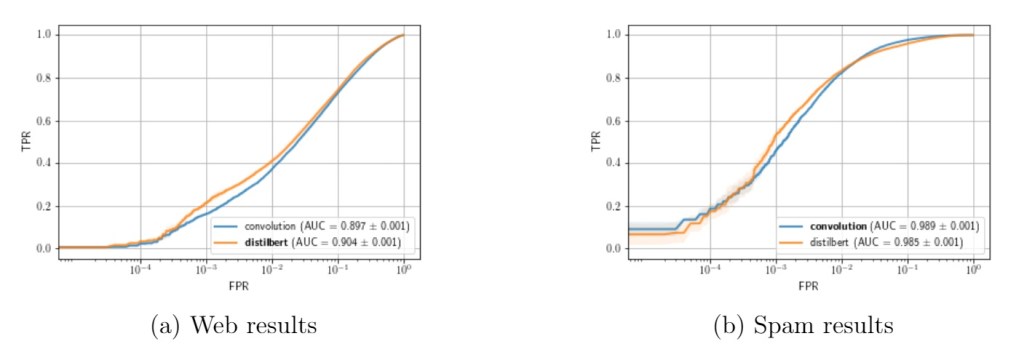
IP representation ROC curves
We can see the results on Figure 4. While the True Positive Rates (TPRs) of the web based model do not look remarkable with either of the models at the lower False Positive Rates (FPRs), the majority of the false positive results come from subnets with overwhelmingly malicious content. The performance of this model (unsurprisingly) won’t support a stand-alone deployment, the model results still provide a valuable addition to more complex protection systems. When we look at the more clustered spam dataset, both the convolutional and DistilBERT approaches show much better results with a TPR of $0.45 – 0.52$, depending on the approach, at a FPR of $10^{-3}$.
Additional features
While the Hilbert curves delivered some goods news, in terms of confirming the structural bias, they also revealed that we have multiple blind spots in our data: blocks of IP addresses with few or no labels. Similarly to how some ISPs are less cautious about hosting malicious infrastructure, some registrars or DNS services may be less strict about malicious domains. This suggests another angle of attack to help supplement the limited IP data: singling out “bad” DNS services or WHOIS details (or WHOIS masking services), under the assumption that threat actors might use some preferentially.
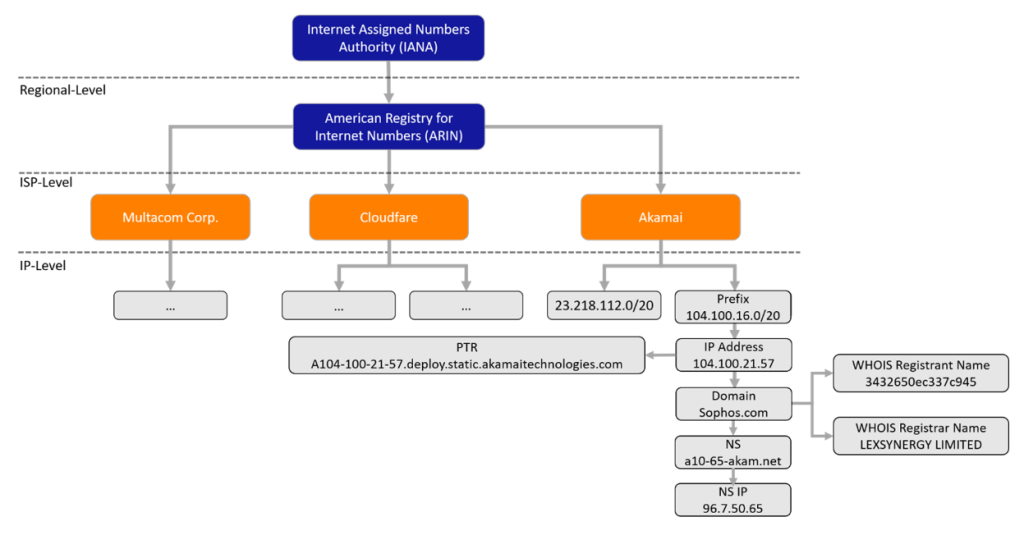
Extended Infrastructure hierarchy
There are also additional inherent features of an IP address we can augment our data with. The internet service provider (ISP) of an IP address is publicly available information, as is the hosting country of the provider.
If we have the domain at our disposal as well, we can augment our feature set with rich information, like the nameserver resolving the A (which maps a domain name to the IP address) and PTR (resolves an IP address to a domain or host name) records of the domain, the IP of the nameserver, and the WHOIS registrar and registrant of the domain.
We efficiently extended our convolutional model to be flexible enough to handle any additional feature that might be present to improve accuracy of the predictions. For the spam dataset we don’t have access to the domains, therefore we only use IP based features. For the web based dataset, we had access to most domains. On Figure 5 we sketch out the relationships of some of the additional features we used: ISP, PTR, nameserver, the IP of the nameserver, and finally the registrar and the registrant of the domain.
In order to incorporate the textual features in our convolutional neural network, we first needed to convert the variable length strings into numeric vectors of fixed length. Because the cardinality of these features was too large to allow for one-hot encodings, we used feature hashing to convert the space of strings into a 1024-dimensional vector.
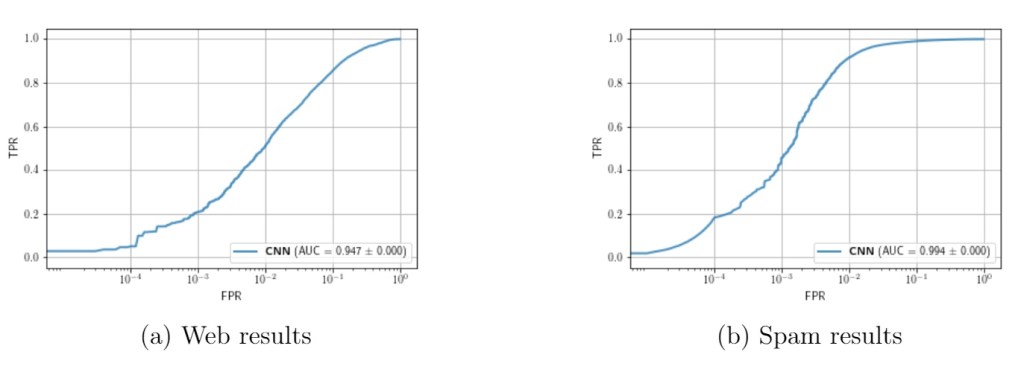
Extended feature set results with the CNN approach
ISP encoding
The IP space assigned to certain organizations might not be contigous in the dataset, and as we have seen previously our dataset does not cover the whole IP space. Observing a disproportionately malicious organization in one segment of the IP space may allow us to generalize the knowledge to a different segment owned by the same ISP where we might lack detailed IP data. However ISP as a feature might not be present at inference time, depending on the application of the model, and it is one of the more important features from the result of Figure 6. Certain parts of the IP addresses reflect their connection to the providers infrastructure, so it might be possible to infer the provider from the IP address only.
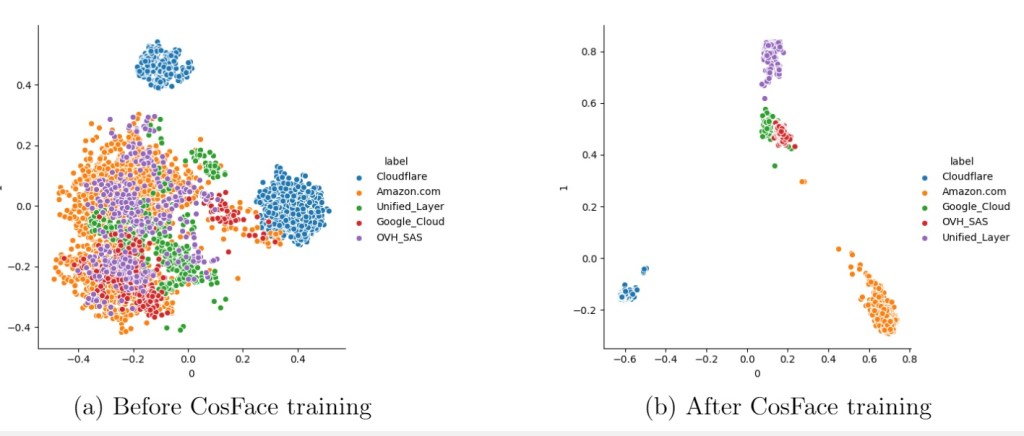
First two principal components of the ip representations
Utilizing a loss function called CosFace allows us to train a model with the objective of labeling IP addresses with their respective providers. With this approach our goal is to map the IP representations to a common region (in some abstract embedding space) based on their ISP, essentially compressing an ISP lookup table on the available data into a model model, which can then be incorporated into our original model. The results of incorporating this information are in Fig 8; while the IP-to-ISP embedding approach does not quite reach the same level of accuracy when both IP and ISP are available and used directly, we do see a significant improvement over the case when only the IP address is available.
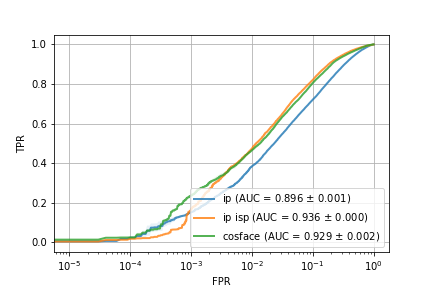
{IP vs IP and ISP vs IP and ISP pretrained mode
Interpretability
We generated a set of 10M routable IP addresses randomly, and visualized the decision boundaries of our convolutional network as a heatmap on a Hilbert curve. For this visualization we used the IP and the internet service provider as our only input. Looking at the result on Figure 9, and comparing it with the data plotted in Figure 2, we can see the model successfully picked up the malicious clusters, and identifies logical heatmaps over the IP space.
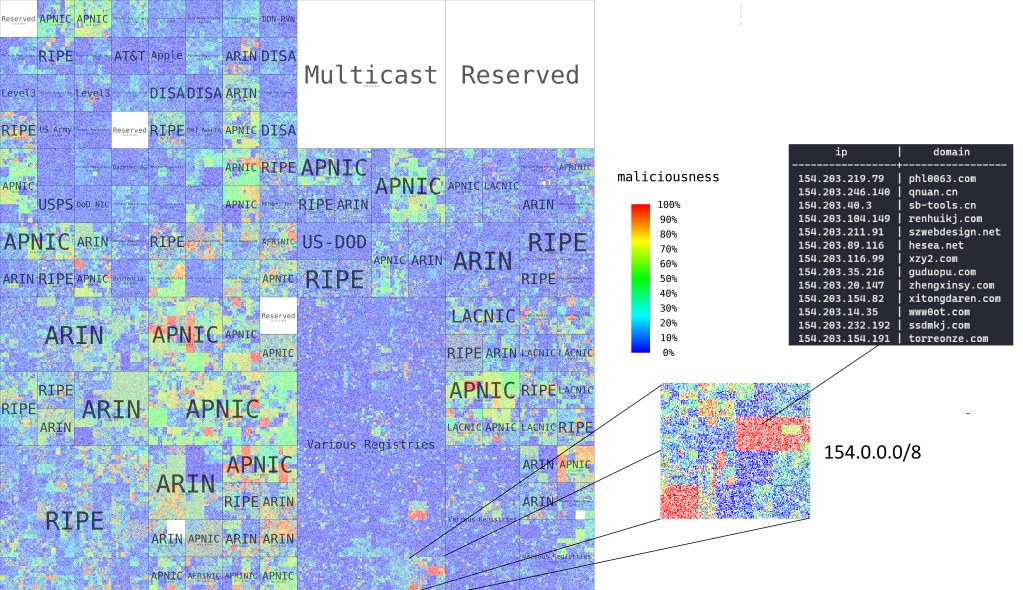
Untresholded heatmap of maliciousness probabilities
Conclusion
In this post we have demonstrated various applications of two forms of deep neural networks, a convolutional network and a pretrained DistilBERT model, to the problem of detecting “bad neighborhoods” in the IPv4 address space. The convolutional approach can benefit from publicly available DNS, and whois features. While the models trained on the web dataset provide a weak signal best combined with other tools, the results are surprisingly good given the limited information in an IP address, and retains the advantage that, for two-way communication to be possible, the IP address is a fundamental input available in any context where network communication is taking place.