Any good attack-chain usually involves tricking users at some point, whether it’s getting them to run a malicious file because they think it’s a video, open an infected PDF because they think it contains important financial information, or click a link because of the promise of easy money. While the risks of social engineering-based techniques like these are difficult to mitigate, the simplistic nature of them can be a double-edged sword for attackers and a boon for detection systems.
Attacks that rely on social engineering are usually carried out en masse and therefore are targeted at the lowest common denominator: users lacking tech savviness or users who are in an exploitable state of mind. As such, they typically aren’t very sophisticated, and given a moment to thoughtfully consider the attack, most users would probably be able to see through the deception. Thankfully for defenders, the simplistic nature of these tricks means that they follow predictable patterns, which can then be used for detection. For example, including the words “free” or “cash” in a URL might entice users to click on it, but those words can also become triggers for a detection system to red flag on.
So what would happen if we trained a machine learning model to take that extra moment of thoughtful consideration for you? We sought to answer that question by building an malicious URL detector:

In the demo above, the user is typing a URL and our machine learning model is analyzing it in real time to produce an determination regarding the safeness of that URL. The user can make adjustments to get immediate feedback on whether those adjustments make the site more or less likely to be malicious. As you can see from the above gif, our model has learned to identify certain “red flags”. such as unencrypted pages (i.e. those using HTTP). It has also learned to identify a common trick used by attackers which is to take a well-known website such as Google, and make it falsely appear that you are browsing to that website by using it a subdomain: “google.securesite.com” in this example. The model learned to identify these suspicious patterns without any human guidance or expertise by training on over 100 million benign and malicious URLs.
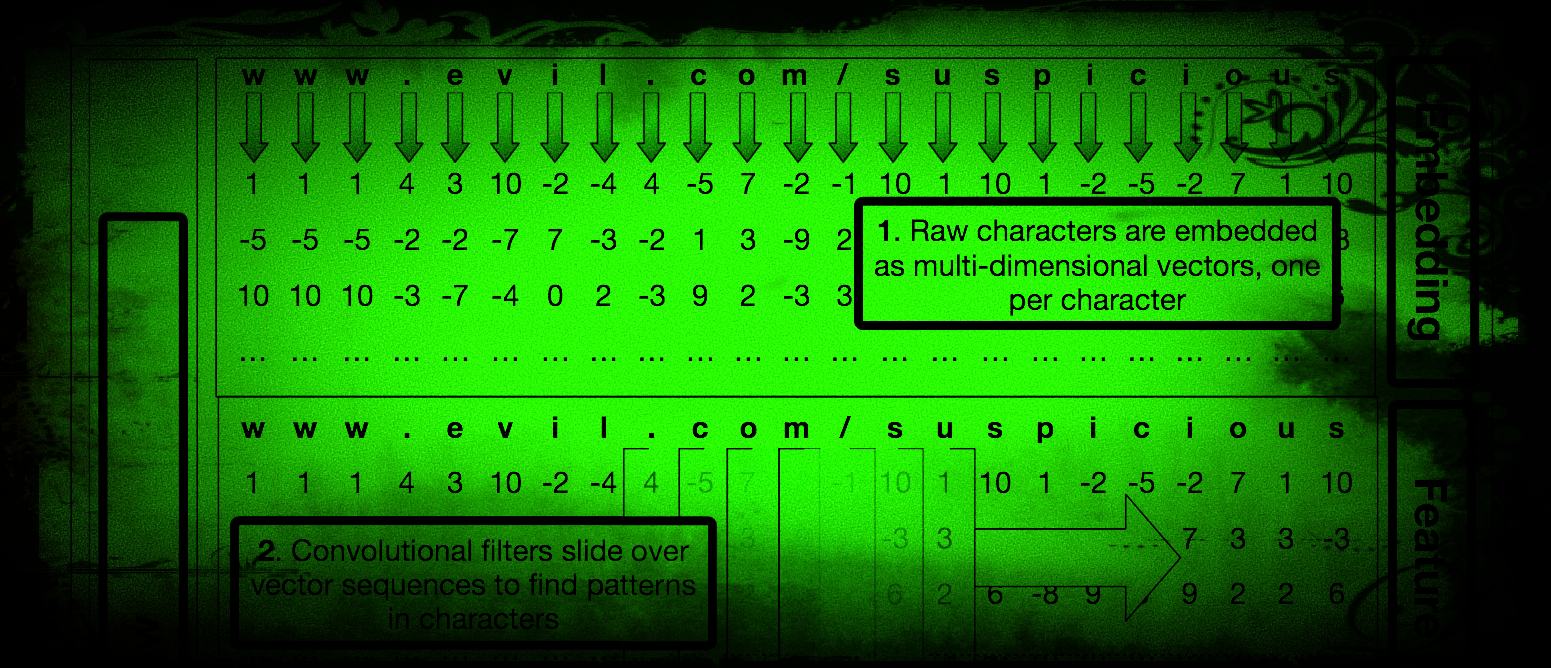
The model’s architecture is fairly complex (see here for the full technical treatment), but in a nutshell it uses a combination of character-level embeddings and a convolutional neural network. At a high level, this means that the model operates on a character-by-character basis and must learn to recognize meaningful patterns of characters such as “g – o – o – g – l – e” on its own. To do this, the model reads the characters of the URL from left to right much like a human would and slowly learns what chunks of characters (i.e. words) are important to consider when looking for a malicious URL.
One novel aspect of our approach is that instead of feeding our model literal characters, such as “g”, and “o”, it is fed “embeddings” of these characters. These embeddings are high-dimensional numerical representations of the letters, which give the model a much richer sense of the context in which the letter is commonly found. For example, the embeddings for “A” and “Z” may indicate some similarity between the two letters due to both being upper case. This approach is less literal than operating on the exact letters of a URL and thus allows our system to be more flexible in its scoring of URLs. For example, in the subdomain trick shown above, it’s not hugely significant that the exact text, “securesite”, is placed between “google” and “com”. What matters is that ANY text is placed there. The embeddings work in combination with the convolutional neural network to give the model a way to encode general relationships between letters in a way that it can later combine them into useful “rules” or “patterns” for detecting malicious sites. The embeddings contribute to this while simultaneously containing enough information about individual characters for the system to be able to learn exact words like “google” or “paypal” when necessary.
The demo above shows the URL model being queried in real time as the user types the URL, however in most cases malicious URLs are encountered in static links found in emails, word documents, and webpages. One aspect of URLs that lends itself to social engineering attacks is that any text can be turned into a malicious link, including text that looks like a legitimate URL: www.google.com. Some attacks even swap similar looking letters such as lower case L’s and upper case i’s, or zeroes and O’s, thereby obfuscating the true destination of the link. As such, verifying the nature of a URL is a very challenging task for humans, and even security-aware users who haven’t had their morning coffee yet may fall for the malicious link in a seemingly benign email. By detecting such a link simply based on the characters within it, the malicious content on the webpage never gets loaded and we can stop the attack in its tracks.