Attention conservation notice: This is a slightly expanded version of a Twitter thread I posted back in January 2020. If you already read that there’s not a whole lot more that’s new here.
While simple deep learning models, like feed foward networks, can be fairly simple to manage, as the models get more complex and use more submodules, fancy operations, and conditional logic, debugging them becomes more and more difficult. This goes double if you’re working in an adversarial setting like infosec, where the Bad Guys are often actively trying to thwart you.
Your first sign of trouble often comes when you notice that your model doesn’t seem to be learning anything; either your loss doesn’t change at all, or the model gets down to essentially outputting the class probabilities, or it seems to be outputting almost exactly the same thing every single time.
Step zero – getting ready to debug
Have you turned off all sources of randomness and variation?
The very first thing you want to do is turn off all sources of randomness and ‘freeze’ the model. You don’t want Dropout to be on, you don’t want BatchNorm moving averages to update, and you want to swap out any sampling behavior with some sort of constant. If this accidentally ‘fixes’ the issue, then try a consistent seed instead.
Do you have a minimal (non-)working example?
Next, find the smallest possible dataset that reproduces the problem. You want to be able to iterate as fast as possible; that means not trying to fit the full data. If you can find 100,000 or even 1,000 samples that let you reproduce the issue you’re seeing, that will speed up your experimentation significantly. The worst and most expensive problems to debug are the ones that need 300 million samples to trigger.
My model doesn’t learn anything at all, or the output converges to a constant value for all samples
The first diagnostic check here is to make sure the outputs change when you change the inputs; you want to make sure that information is actually flowing through your model and your clever new architecture isn’t accidentally just outputting a constant value for all inputs. If there’s no information from the inputs getting to the outputs, very often what will happen is that your bias terms learn the mean or base rate.
Is information flow blocked, or is information being lost to saturation?
If it always seems to provide the same output regardless of the input, it’s worth a) trying a few different initializations, b) trying a constant (i.e. a value of 1 for every weight) initialization, and c) changing any saturating activation functions (sigmoid, tanh, etc) to non-saturating ones (ReLU, ELU, or the like) before you decide that no, there really is somewhere in the middle of the model where the information flow is blocked (especially if it’s some sort of recurrent model like an RNN or LSTM).
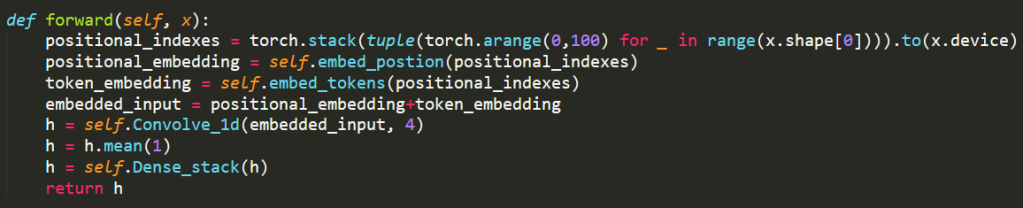
Do you have an operation within your model that is discarding information?
If you’re sure that there’s no information flowing from the inputs to the outputs, then it’s time to check layer by layer to see where the blockage is. Accidental multiplication by zero is a frequent culprit, as is accidentally overwriting or discarding an intermediate value. Follow the chain of assignments carefully through the function to see if you’ve broken it anywhere. Separate out any compound function calls; for instance refactor the following:

To this:

Also note the debug statement at the start of the forward pass; another useful trick is to pass in a minibatch with two different samples and step through the forward method to see if or when the in-process samples become identical.
Is none of that is happening, but the model still learning just the mean / base rate?
You may have broken the connection between your samples and your labels somehow; see the section on that problem a bit further down.
My model learns something, but the final performance is awful
Are you accidentally skipping layers?
If the problem is that the model isn’t learning well enough, then the first test is to take a single small minibatch from your own data and try to overfit the model to it. Can you take 100 or so samples and drive the training loss all the way to zero? (Of course, you need to make sure that you don’t have identical samples with different labels, replace “zero” with “minimum possible” in that case.) Most models are horrendously overparameterized, and if they can’t exactly memorize a very small amount of data you might have a problem. A very common culprit here is accidentally skipping layers via mis-assignment; less common but worth checking for is that you haven’t accidentally stuck a nondifferentiable operation in the middle of your model somewhere.
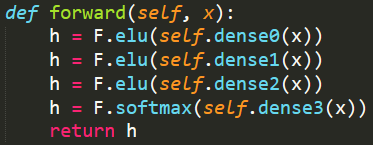
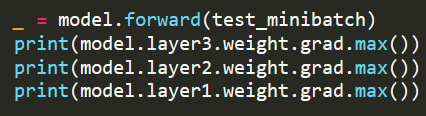
If you’re using PyTorch, checking this tends to be fairly straightforward; do a forward pass on one minibatch and then work backwards through the model, checking the gradients for each parameter. If they come up empty, then that’s where you need to take a closer look. If you’re using TensorFlow in eager mode, you can do something similar, but in a lot of other frameworks this can be tricky.
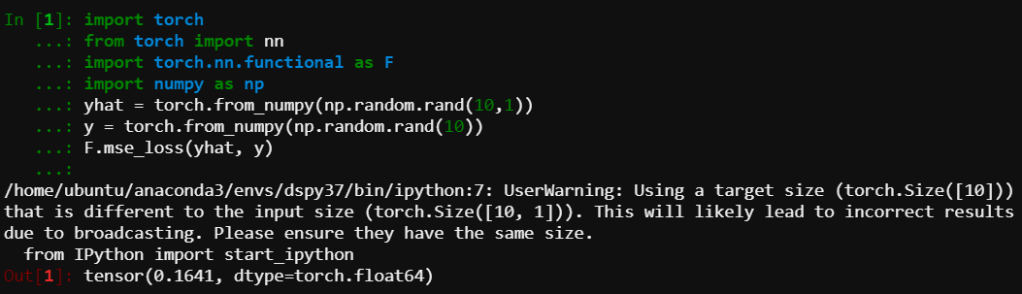
Are your prediction and target tensors exactly the same shape?
Sometimes tensor shapes can be an issue; for instance computing MSE of a column vector against a row vector can often lead to incorrect broadcasting, and incorrect loss values; explicitly reshaping both prediction and target to column vectors is often a good idea.
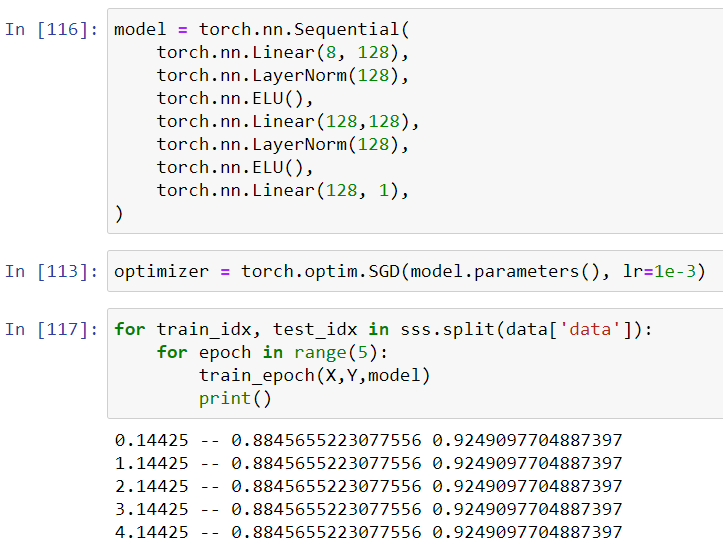
Did you re-initialize your model without re-initializing the optimizer?
Another common (PyTorch-specific) mistake to watch out for — especially if you’re working in an IPython shell or Jupyter notebook — is assigning your optimizer to the wrong model. If you rebuild the model but don’t reassign the optimizer, you’ll be sitting staring at a model that used to train and wondering why it’s not going anywhere anymore.
Have you accidentally broken the connection between samples and labels?
Another slightly less common culprit is in data loading; while most common data-loading tools will manage this for you, if you work hard enough at it you can often decouple your samples from their labels, and perhaps shuffle one without shuffling the other. This, again, will typically drive your model to update weights, but stop improving when it predicts a constant score, typically mean, median, some other measure of central tendency, depending on the loss. A related issue is setting some or all of your sample weights to zero. If this is stochastic and correlated with a label, it can lead you to that worst of all worlds: an answer that is plausible but wrong. All of these errors are easier to avoid if you use a stable data loading tool that handles things like shuffling and augmentation for you.

My model “trains”, but the loss goes haywire
Do you have exponential or log functions in your model or loss function?
These can be numerically unstable; if there’s any way to rewrite your model to avoid them, try to do so. If you have to pick, go with logarithms — they’re fussier about the numbers you can put into them, but their outputs are better behaved. Always make sure your inputs are positive, and add a ‘nugget’ to keep it from being zero.

Are you using a pseudo-second-order optimizer?
Optimizers like Adam that try to keep track of higher-order moments can often get thrown off quite badly if your input data is poorly distributed, highly clustered, or sorted by input values (don’t laugh, I’ve seen it) and you aren’t shuffling it. Often just trying again with a different random seed for the data shuffling can help you out. Another thing to consider is explicitly building balanced batches, or trying to ‘precondition’ the model via SGD for a few epochs before switching to a different optimizer; this can help it get into a better-behaved part of the loss surface.
Did you write your own loss function?
If you’ve made your own loss function, test that separately first. Feed it prediction/ground truth pairs where the loss should be zero, nonzero but very small, and fairly large. You’re looking for two common failure modes; first, that you don’t have over/underflows for extreme values that give you inappropriate or NaN results. Next, you want to make sure that you haven’t missed a negative sign somewhere such that you’ve accidentally told your model to do gradient ascent rather than descent. This this is extremely easy to do if you’re doing adversarial training or optimizing against log-likelihood.
Are you initializing your weights at the right scale?
If you’re sure neither of those are the culprits, then a lot will depend on the kind of model; recurrent models (RNNs, LSTMs, and the like) and extremely deep models without any ‘shortcuts’ can often have issues with initialization. It’s worth trying to shrink the weights significantly, or try shorter sequences (if possible) to see if that helps control the behavior during optimization. If you’re doing anything with exponentials or logs, checking to make sure that you’re either a) keeping the input values from blowing up, or b) keeping the input values from going to zero, respectively.
Does your model have trouble with a specific minibatch of data?
Beyond that, there’s a few other things worth checking. First, seed every possible source of randomness — model weights, sample shuffling, any in-model sampling — and re-run the experiment; does the loss go wild at the same point? If so, insert a breakpoint into your sample loader and start checking the results of each intermediate computation to see where it’s starting to go off the rails. If it gets through the forward pass safely, check the behavior of the optimizer. Sometimes — especially with pseudo-second-order optimizers or BatchNorm — a bad-luck run of minibatches that are heavily imbalanced or very similar can mess up the running estimates and cause bad behavior.
Do you ever have single-label or all-zero-weight minibatches?
It’s also worth making sure that no minibatches have either completely homogenous labels, and (if you use per-sample weights) that you don’t have any targets where the entire minibatch has zero weight. While theoretically they shouldn’t make a difference to the optimization problem, in practice, when you have things like pseudo-second order optimizers, they can lead to unexpected results occasionally. Consider artificially balancing your batches, and doing a sweep to remove zero-weight samples, if possible.
Do you simply have a rough loss surface that your optimizer is overreacting to?
It’s also possible that your loss surface is just rough and difficult to safely traverse in some spots; weight regularization and BatchNorm/LayerNorm can help smooth it, Dropout can very often make it worse so so consider turning that down or off entirely. Dialing the learning rate much lower as it passes those rough patches can also sometimes help reduce instability; trying a learning rate scan can often be a useful exercise. If you have data points with identical (or nearly identical) features but significantly different labels within the same minibatch, these can sometimes give loss functions or optimizers headaches; again, in theory it shouldn’t make a difference, in practice it sometimes can.
Finally, looking at data augmentation approaches like MixUp might be worth a try; I’ve never had to try them, but I’ve heard favorable remarks from others.
None of the above problems seem to fit, it’s just not learning as well as I want it to, even on the training set
Does your model have sufficient capacity?
Very often, problems turn out to be much more complex than we think they are. If your model is able to memorize a single minibatch (see above) but isn’t able to achieve reasonable performance on even your training data, it’s worth seeing if hitting it with a bigger stick works. Use this as your excuse to break out the big, bad, SOTA model that’s you’ve been itching to try out but you know is absolutely infeasible for production, turn off any regularization, and give it a whirl. The goal here is just to do well on the training data. If the huge model can drive training loss low enough to satisfy you, that’s a signal to go back to the architecture design stage and try increasing model capacity.
Is label noise bounding your potential performance?
Despite the fact that you’ve probably already checked the features and labels, it’s time to go do that again. Particularly if you’re working on a security-related problem, label noise can be a significant headache. It might just be that you’re at the limit of what your model can learn with respect to intrinsic label noise. If, for instance, you’re trying to evaluate a models performance at a false positive rate of (e.g.) 1 in 1000, and you also have a label error rate of 1 in 1000, you’re just not going to be able to get a useful estimate of error at that FPR. In such cases, you might be forced to spend time and money checking your labels and making sure that they’re good, or try to find a way to redefine the problem so that you can live with the label noise.
Other approaches to dealing with label noise include weak supervision — in which you use a variety of “weak” labeling functions in an ensemble to try to estimate the true label — and active learning, in which you try to train a model to identify the most important samples to label. In either case, you’re looking at a significant investment of time and technical expertise. It might be worthwhile trying to reframe the problem in a way that you can live with the noisy data.
The model performs fine on my training data, but falls apart on test data
Are you sure your random train/validation/test splitting is actually random?
If you’re relying on some sort of external signal (sha256 values, someone else’s train/validation/test splits, file name, or so on) to split your files, it’s quite possible that the splits are biased. Try a training run where you split them based on uniform random sampling, and see if it improves anything. If so, reconsider how you’re doing your sample splits. The one big exception to this is if you’re splitting based on time, in which case…
Is there any chance of concept drift?
Finally, if you’re looking at time-split data (which, if you’re doing security data science, you probably should be) it might be worth removing the time dependency on your train/validation/test split. If your validation accuracy suddenly improves, then you might have concept drift in the data. While this is good insofar as it justifies the use of time-splitting, it also is a good indication that you might need to retrain the model much more often than you’d planned while in production.
Conclusion
Debugging deep learning models efficiently can be as much art as science, especially as you move into more complex architectures, custom loss functions, and security problems where label noise, adversarial examples, and concept drift can become significant challenges. Hopefully the suggestions above help you get started with your own model challenges (if you have them). Good luck, and may all your objective functions be convex!