Here at the Sophos AI team, our most common goal is to develop deep learning models that inspect a file and spit out an accurate maliciousness score. We’ve gotten pretty good at it. Custom deep learning architectures, clever input features, and hundreds of millions of training files allow our models to become really good at recognizing malware, even malware they’ve never seen before.
Of course, they’re not perfect. If we train a model on all our available data, it’ll be able to classify new, never before seen benign and malicious files over the next week really well. But in six months, the threat landscape will have changed so much that the model will struggle to correctly classify the new files that are now quite divergent from the original files it trained on.
You can see this effect in what we call a ‘time-decay’ plot – it shows a model’s accuracy (y-axis) ‘decaying’ over time (x-axis). The vertical line down the center indicates the last day that the model saw training data from. All of the files the model is classifying are files it has never seen before (didn’t exist in the training set), but because the distribution of files changes over time, the accuracy still generally gets worse and worse at classifying files the further it gets from the training date.
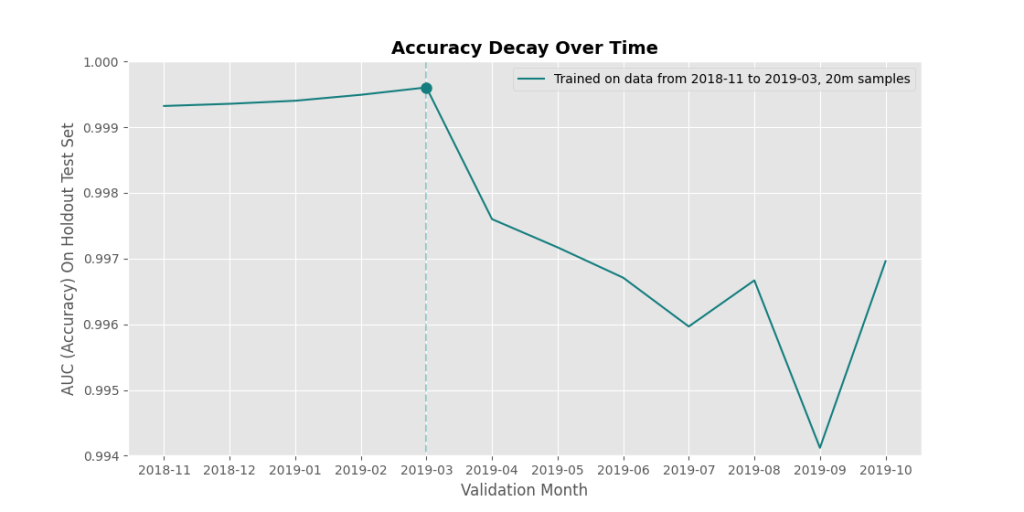
OK cool, so what? Well, ideally we’d like to just straight up release updated models all the time. If you train your model on new data coming in every day and release it, then it’ll never have a chance to decay in accuracy. Sweet!
But of course, there’s a catch. Enter limited budgets stage left, and catastrophic forgetting stage right.
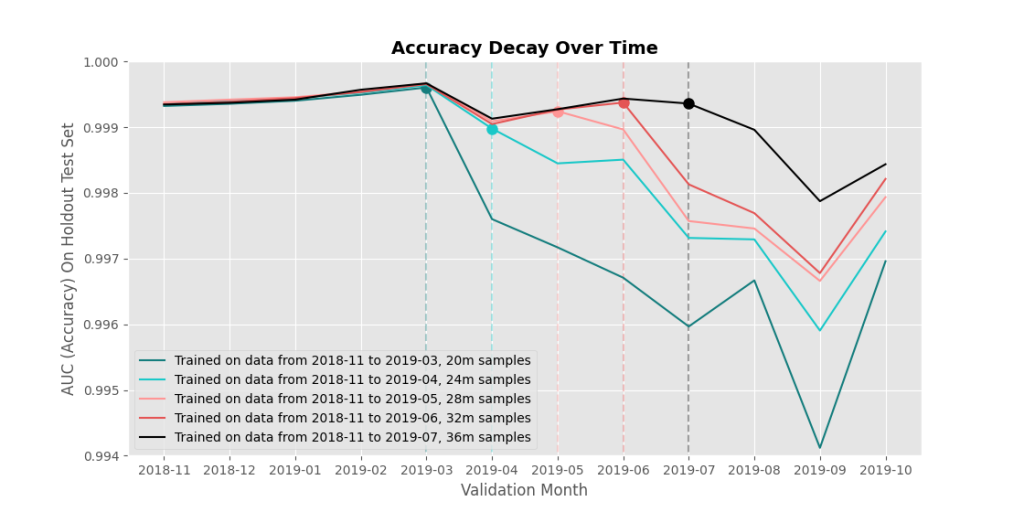
First, the budget problem. The problem with training a new model from scratch every day is that the computing resources alone are expensive – in the thousands of dollars, depending on the model you’re training. And depending on the training setup you have (multi-GPU training or much slower single-GPU training), the training process can take days or weeks. If we’re juggling twenty models that we’d like to weekly versions of, each costing $2,000 to train, that’s about two million dollars a year just in computing resources. It’d be great to figure out a better solution – we could save a bunch of money and slightly reduce our company’s carbon impact at the same time.
This leads us to the catastrophic forgetting problem. The simplest way to train a new model super quickly and cheaply is to take a preexisting model and just fine-tune it (train it) on your most recent data. Say you have a model $M_0$ trained on all past data. Next week, instead of training a new model from scratch on the same data + the new data from the last week to get $M_1$, you can train $M_0$ on just last week’s data to get $M_1$.
Tragically (thankfully?), neural networks don’t work like human brains. Doing this tends to cause $M_1$ to overfit to the new data, and “catastrophically forget” how to classify the old data. Why? When human brains learn, we’re presumably updating only very small parts of our brain to incorporate the new information – and because of our years of experience and generalization capabilities, that works well. When we teach neural networks to learn something new, the general practice is to feed it some input, see how it got things wrong, and then update every single parameter in the neural network in order to correct that wrong. So perhaps you can see how if your neural network is only training on a different, new set of data, it might end up forgetting (read: overwriting important parameters with new values) important old stuff – like the ability to detect older malware files.
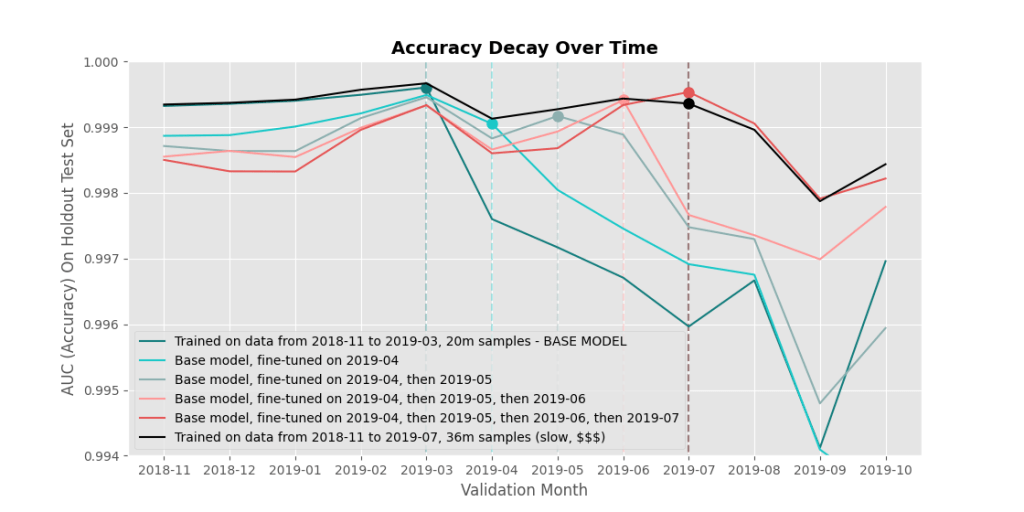
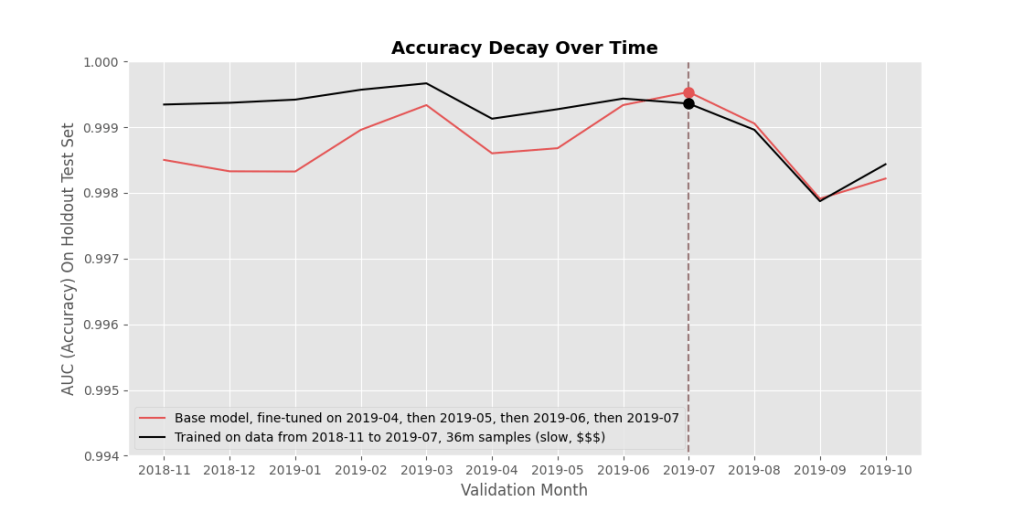
In the plot below, you can see this happening. We start off with the dark teal line we saw above, representing a base model that has been trained on data before 2019-03. The light teal line represents what happens when that base model is taken and fine-tuned (trained a bit more) on only data from 2019-04. The model gets better at classifying newer samples, but worse at classifying older ones. Next, the grey line represents the 2019-04 model fine-tuned again, but this time on data from 2019-05. The light pink line represents the 2019-05 model fine-tuned on 2019-06, and finally the red line represents this 2019-06 model fine-tuned on 2019-07 data. Each successive fine-tuning helped the model learn new data, but it forgot more and more about the past. The black line, on the other hand, is essentially our goal. This model is a model that was trained on all data up until 2019-07, all at the same time.
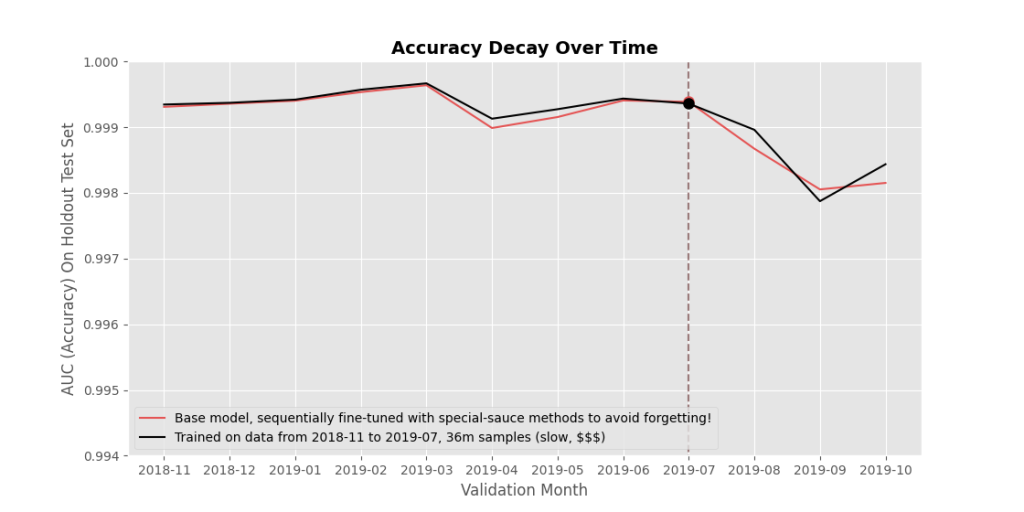
If we can get sequentially fine-tuned models to match or beat accuracies of a model trained all at once, then we have a path to deploying accurate models very quickly and very cheaply.
Again, in Figure 4, red: sequential fine-tuning that means quick and cheap model releases, but ‘catastrophically forgetting’ past lessons (lower accuracy) is an issue; black: retraining everything from scratch means slower and more expensive model releases, but consistently high accuracy across past and current data. We want to develop methods to push up the red line to match or beat the black line, without the computational costs of retraining from scratch!
There are various methods in machine learning literature aimed at minimizing this catastrophic forgetting effect. In this blog post, I’ve tried to explain catastrophic forgetting, why it’s a problem, and how it relates to detecting malware. In my next blog post “Catastrophic Forgetting, Part 2”, I’ll do a deep dive into some of the different approaches we’ve tried.
For now though, Figure 5 can be a teaser-trailer ;).