
Hundreds of millions of events. Tens of thousands of triggered rules. A thousand incidents. Every week. That is the reality of the modern cyber threat landscape and the sheer volume of alerts that the Sophos MTR (Managed Threat Response) team tirelessly resolves to protect our customers from threats. In a step towards improving response times, automating defense, and reducing analyst workload, we at Sophos AI have developed a new model that predicts which alerts analysts will find most critical. The model allows us to filter alerts that are likely false positives and sort alerts based on their criticality.
Here’s how the system works. Sophos ingests immense amounts of data across customer networks in the form of variable, evolving, semi-structured alerts. A growing set of rules filter suspicious observations; but, as with many prior systems, these rules are prone to extraordinarily high levels of false positives because missing a real instance of malicious behavior can be catastrophic. Our model acts on top of the traditional paradigm as a false positive whack-a-mole, prioritizing and suppressing alerts in a more intricate, data-driven manner than manual rules can achieve. The model uses over 200 features that we automatically extract from raw sensors, manual rules, and existing ML models. Our MTR analysts produce labels during their alert investigations, which we use to create an AI-powered, human-in-the-loop operations center.
This automatic featurization is a core part of the modeling process. Because data collection is constantly evolving to handle new threats, even the schema of alerts can rapidly change. Adjusting for these changes can require wide coordination amongst different teams, and retraining models becomes a time-consuming, manual process. Instead, our training and deployment pipeline can automatically adapt to new alert types and schema changes without human intervention because we use an auto ML-like system that analyzes the types, quantities, and distributions of the features to refine the model inputs.
The model itself uses XGBoost, which trains and predicts efficiently while outperforming other baselines. The results speak for themselves: not only does the model bubble up incidents that require reaching out to our customers, but it also drops many false positive incidents entirely.
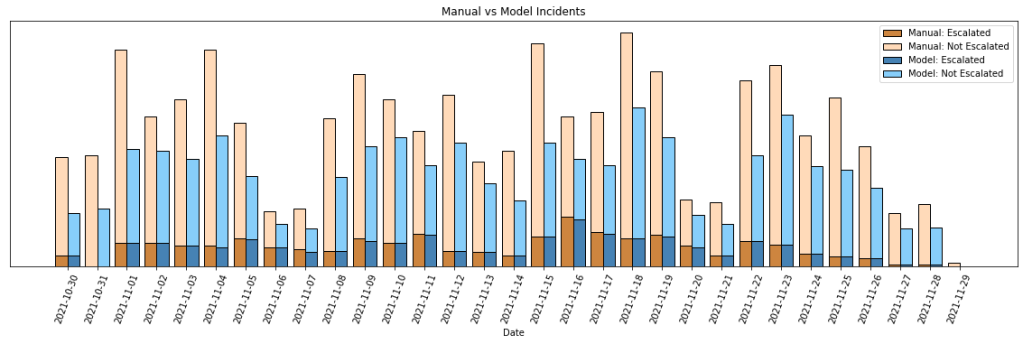
In the figure above, we show the number of true positive and false positive incidents on our actual MTR and simulate the data if our model were applied to the same set of alerts. The light brown bars show all the false positive incidents that the analysts manually resolve per day. The light blue bars show the amount of false positive incidents that would remain after the model processes every alert that day. The main takeaway is that the gap between these bars is the amount of false positive cases that have been entirely eliminated, totaling to a 39.7% decrease in the current figure.
In summary, the benefits of our approach are multi-fold: the initial filter rules can be more aggressive to avoid missing catastrophic attacks, even if they cause more false positives; the number of alerts that make it to human analysts can be significantly reduced, scaling their efforts to more customers; and diagnostics even within a single incident can be prioritized to improve analyst efficiency. Although human expertise is a crucial aspect of cyber defense, machine learning can scale those efforts to more customers and diverse threats. This model is in active development with the goal of incorporating it into our MTR analyst workflows and customer-facing XDR platform.