Introduction
The use of deep neural networks has significantly improved the performance of machine learning in fields such as image recognition, machine translation, and malware classification. A key lesson from recent deep learning success is that, as we scale neural networks, they tend to get better in ways that can be game-changing. In this post, we explain how supercomputer-scale neural networks can be used for machine learning security applications in new and powerful ways. We will demonstrate two cybersecurity use cases that would not have been possible with smaller models: detecting spam messages with few training examples and generating human-readable explanations of difficult-to-parse commands.
GPT-3 and few-shot learning
GPT-3 is a pre-trained, large-scale language model, and its flexibility and accuracy are game-changing. If input and output data can be converted into text, GPT-3’s potential applications are endless. For example, it is possible to ask GPT-3 to write working Python code from a function description. Furthermore, it is possible to build a classification application with only a few examples.
It is usually easy to find an unlabelled dataset in the cybersecurity domain; however, it is often time-consuming and difficult to create a labelled dataset for training a traditional machine learning model. Traditional machine learning models trained with few examples commonly exhibit overfitting problems, where they do not generalize well to previously unseen samples. On the other hand, GPT-3’s few-shot learning only requires few annotated training samples and outperforms traditional models. As GPT-3 has been trained in a self-supervised way on a large general corpus, it turned out that it can do well on multiple classification problems with just a few examples. The ability to generalize from just a few labelled examples makes GPT-3 potentially a powerful tool in cybersecurity where for problems where there are very few labelled examples. Below we explore two such use cases.
Spam detection from few examples
It is challenging to train a high performing spam classification model only with four benign ham and four spam samples because traditional classification models often require a large training dataset to learn enough signals. However, as GPT-3 is a language model pre-trained with large scale text dataset, it can recognise the intention of a classification task and complete the task with few examples.
In few-shot learning, prompt engineering, which designs the input text data format for text completion tasks, is an important step. Figure 1 shows the prompt for a spam classification task. An instruction and a few examples with their labels are included as a support set in the prompt, and a query example is appended in the last section. Then, GPT-3 is asked to generate a response as its label predication from the input.

Figure 2 compares the classification F1 results between traditional ML models and few-shot learning using GPT-3. As can be seen, few-shot learning using GPT-3 significantly outperforms traditional ML models such as logistic regression and random forest. This is because few-shot learning leverages the context information from the given examples and selects the label of the most similar example as its output. Few-shot learning with GPT-3 does not require any re-training, but it allows us to build a powerful classification model with simple prompt engineering.
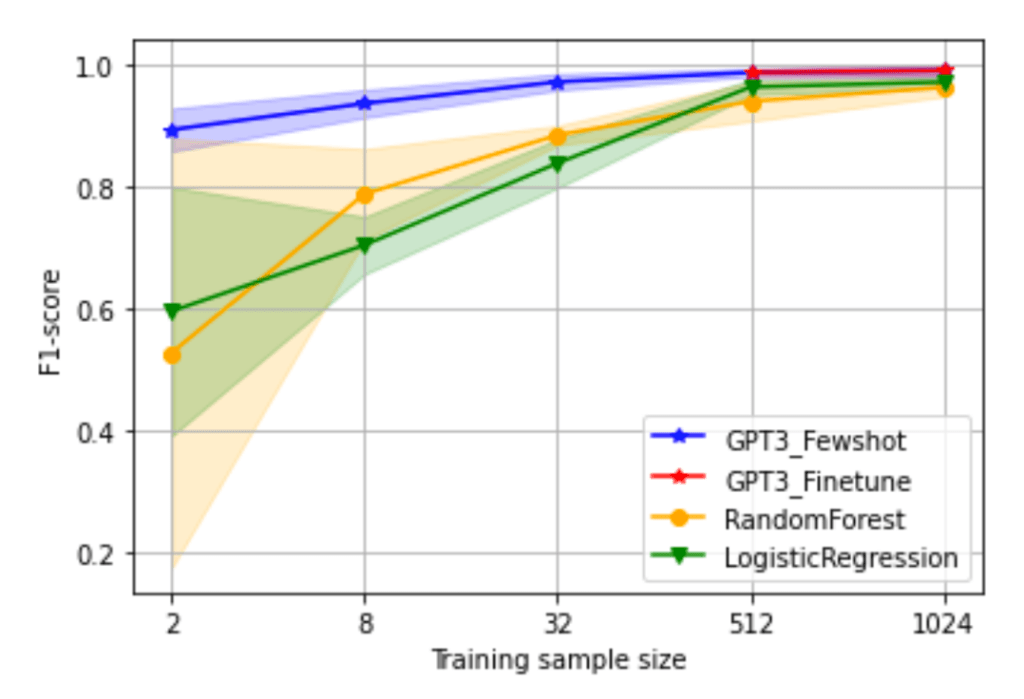
There are a few ways to improve few-shot learning classification performance. One way is to increase the number of examples in the prompt, but there is a limit to how many samples can be used due to the GPT-3 input memory limitation. Another approach is fine-tuning, which allows us to use all the examples for fine-tuning GPT-3. As the plot shows, fine-tuning with more samples of 512 and 1024 further improved classification performance over few-shot learning with fewer samples of 2, 8 and 32.
Generating valid explanations of complex “living off the land” commands
Reverse engineering command lines is a difficult and time-consuming task even for security experts. It is even harder to understand living off the land commands, which are long and often contain hard-to-parse strings. Our second use case is to create a GPT-3 application which can translate a command line into a natural language description.
GPT-3 can write working Python or Java code from a given description of the code, which is extremely useful for converting a command line to a description. It is also possible to ask GPT-3 to generate multiple descriptions from one command line and the output descriptions are provided with word-level token probabilities to choose the best candidate. However, it is important to note that the description with the best token probability does not always guarantee the best description.
Our approach to selecting the best description out of multiple candidates is to use a back-translation method, which will choose the description that can generate the most similar command line to the input command line. The first step of our method is to produce multiple descriptions from an input command line. Then, a command line is translated back from each description. The last step is to find the best matching command using similarity scores and choose its corresponding description as the best solution. Similarity scores between commands can be measured by the cosine similarity between the embedding vectors representing those commands. In addition, similarity between the generated command line and its tags and the description can be measured. Its final similarity score is the weighted sum of those scores. We also find that identified tag information from command lines was useful to provide additional context. For instance, the tag about account discovery in Figure 3 guides GPT-3 to describe the command’s behaviour in the generated description. Additionally, we discover that the first and second-best descriptions can provide complementary information and their combination produces the best result in our experiments. Figure 3 demonstrates that the description from our back-translation approach provides detailed information about malicious activity.

Conclusion
GPT-3 is a game-changer for cybersecurity, as it can detect spam and analyse complex command lines with few examples. Our source code for two GPT-3 applications is available in our github repository, https://github.com/sophos/gpt3-and-cybersecurity.
The flexibility of GPT-3’s few-shot and fine-tuning approaches makes it well-suited for constantly evolving cyber threats. We anticipate that we can tackle even harder cybersecurity problems with even larger neural network models.