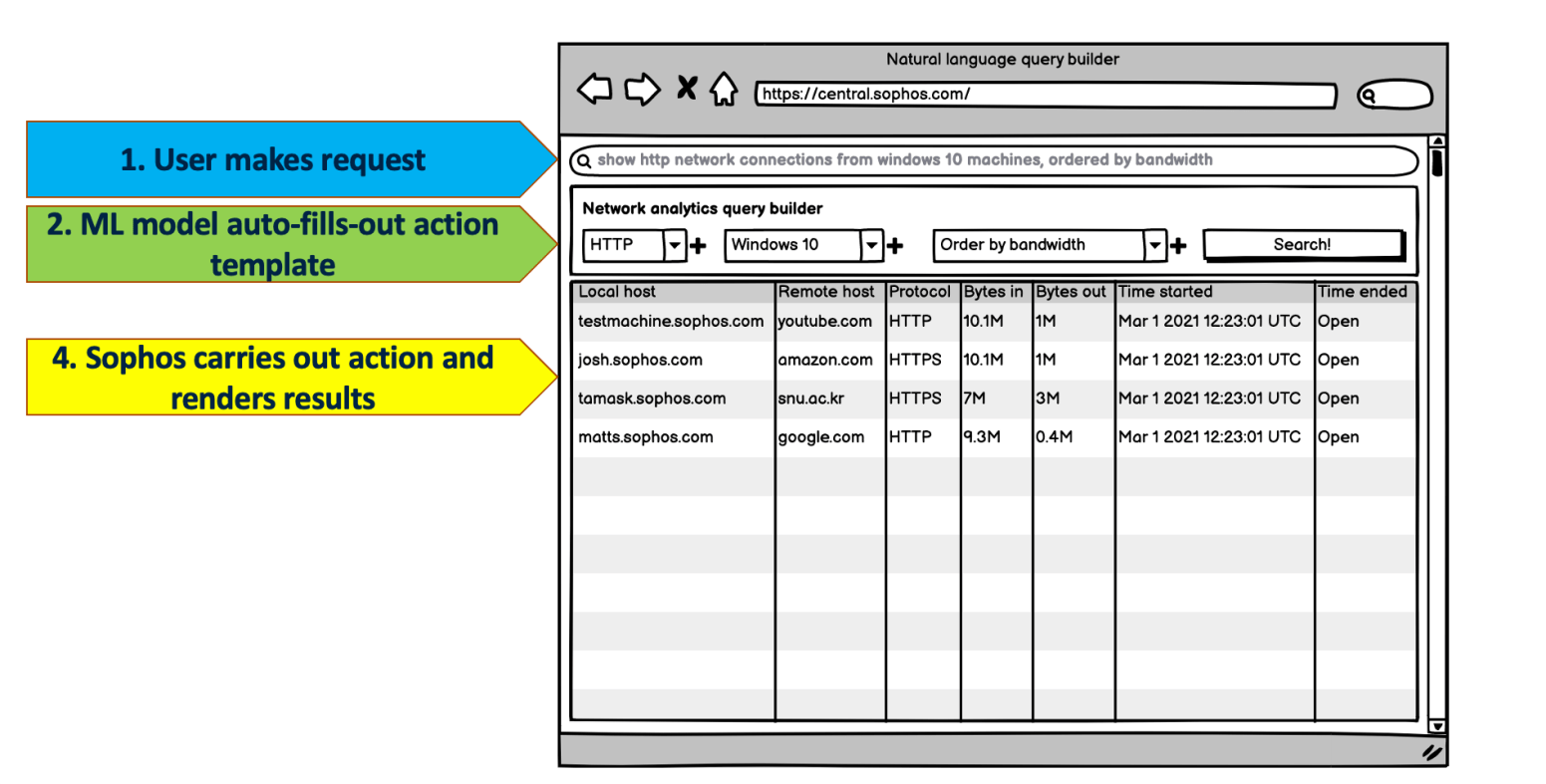
Introduction
Many organizations are transitioning their security management to the cloud, where it is much easier to collect and access security data across the entire security portfolio. Rather than trying to develop the infrastructure from scratch or purchase a Security Event and Information Management (SEIM) solution, security data is frequently collected and managed instead by 3rd party services commonly referred to as extended detection and response (XDR) services. While the data collection, normalization, and aggregation are now managed by an XDR service the onus is still on the customer properly query the data to find the relevant information. Given the diversity of the collected data from the various systems and sensors the queries are frequently too complicated for an end user to be able to create without an extensive learning overhead. Certain additions to the interface can make this job easier, for example the Sophos XDR solution provides comprehensive pre-written templates for both security experts and IT administrators to help guide users in finding the right data. While this potentially provides users with a starting point it still takes a user time to find the right template and convert it to their specific needs.
In this blog post, we describe a prototype natural language interface that can translate common user queries written in natural language into direct SQL queries that run on top of the Sophos XDR solution. The natural language query interface would allow users to better interact with the system by quickly generating working initial queries as a starting point into a deeper exploration. The main challenge in developing such a system is the difficulty in collecting large and diverse sets of training examples to train a good enough machine learning model. In our work instead of attempting to generate a large training corpus we fine-tune a GPT3, a Large Language Model created by OpenAI, and take advantage of its generalization ability to learn the natural language to SQL translation from just a few samples. Additionally, we use also use the GPT3 for automated data augmentation strategy to further improve our results.
Translating questions to SQL queries using GPT-3’s few-shot learning
GPT-3 is a language model that has shown remarkable results in many NLP (Natural Language Processing) tasks, including translation and text generation. With that in mind, we form our query translation task as a language translation task and apply GPT-3’s few-shot learning approach as our baseline. Few-shot learning is a type of transfer learning that uses a pre-trained model to quickly adapt to new tasks with a small number of examples in the prompt.
In few-shot learning, we provide a few annotated training examples in a prompt and ask the model to learn from the given examples and then complete a new task. This allows us to train our model using a small training dataset. We feed our model natural language question-SQL pairs, and then ask it to translate new questions into SQL statements. As you can see in Example 1, we design our input data to include schema details and two query examples, so that the model can generate a SQL statement for the last question. This not only helps the model learn the relationship between questions and DB schemas, but also teaches it the mapping between questions and SQL queries. By including column names and data types in the schema section, we give the model the information it needs to make these connections.
| ### Schema for Process_table process, TEXT user, TEXT path, TEXT host, TEXT ### Translate the following Question into SQL. Question: List all processes named powershell.exe SQL: select * from Process_table where process=’powershell.exe’; Question: Show me the processes that were executed by the root user SQL: select * from Process_table where user=’root’; Question: Find all processes that were executed on DEMO servers SQL: |
| completion: select * from Process_table where host=’DEMO’; |
GPT-3’s fine-tuning with augmented data
Few-shot learning is simple to use with a small training dataset, but translating complex or unseen translation questions with limited examples in the prompt can still be challenging. In few-shot learning, GPT-3 can learn from the limited samples in a prompt, but it cannot reuse the previous learning for a new task. On the other hand, fine-tuning allows us to continue training GPT-3 with more samples. Increasing the number of diverse training samples and fine-tuning a model with the augmented samples is one of the most effective methods for improving translation accuracy. We found that it is possible to generate various high-quality examples by combining where clauses from existing training samples.
In Example 2, we show our data augmentation approach. We randomly select two examples from a training set and create a new SQL statement by merging two SQL statements. To generate a natural language question, we use another few-shot learning setting, where we provide examples in reverse order and ask GPT-3 to generate a new question for the combined SQL query. For instance, the combined where clause about process and user information was generated from the first and the second where conditions. The generated completion correctly describes the two conditions in a natural language query.
Our data augmentation method is simple, but we can generate as many new examples as we require for augmented training samples. The variety of new examples allows fine-tuned models to learn new mappings between schema and complex conditions, which also helps them adapt to unseen questions for new tables.
| ### Translate the following SQL into a Question. SQL: select * from Process_table where process=’powershell.exe’; Question: List all processes named powershell.exe SQL: select * from Process_table where user=’root’; Question: Show me the processes that were executed by the root user SQL: select * from Process_table where process=’powershell.exe’ and user=’root’; Question: |
| completion: Show me all processes that were named powershell.exe and executed by root user |
Experiments
To evaluate the performance of both similar and unseen out-of-distribution data, we divided our small training dataset of 164 samples into an in-distribution and an out-of-distribution group. In-distribution data is data that is analogous to the training data, while out-of-distribution data is dissimilar. In our experiment, we fine-tuned GPT-3 models with training samples from three XDR (Process, Alert, Network) tables and assessed the accuracy for test samples from the same tables in the in-distribution setting. In the out-of-distribution setting, where the schema information of the test tables was provided, we tested with samples from an unseen XDR (File) table.
We experimented with Curie and Davinci models, which are two of models in the GPT-3 family. We compared three approaches, few-shot learning on a few examples as described in the previous section, fine-tuning with and without data augmentation. The Davinci model has more parameters and is more powerful than the smaller Curie model. As can be seen from Table 1, the largest GPT-3/Davinci model with few-shot learning achieved 80.2% and 70.5% accuracies for in-distribution and out-of-distribution samples, respectively. In contrast, the smaller GPT-3/Curie model with few-shot learning showed significantly degraded performance on unseen data. These results demonstrate that a bigger GPT-3 model is more likely to generalize better than its smaller counterpart.
| GPT-3 model | Learning method | Accuracy for in-distribution data | Accuracy for in-distribution data |
| Curie | Few-shot learning | 34.4% | 10.2% |
| Fine-tuning | 70.4% | 70.1% | |
| Fine-tuning with data augmentation | 82.1% | 79.4% | |
| Davinci | Few-shot learning | 80.2% | 70.5% |
| Fine-tuning | 83.8% | 75.5% | |
| Fine-tuning with data augmentation | 89.1% | 82.3% |
We employ an augmentation technique in which we randomly select two or three samples from a training set and combine their SQL where clauses to form a new query. To generate higher quality and more diverse training examples, we use the chosen samples to create SQL-to-Question examples, but in reverse order. This doubles the number of training examples. Our fine-tuning with data augmentation significantly improves the performance compared to the baseline fine-tuning method without data augmentation. This approach is effective in both in-distribution and out-of-distribution settings, demonstrating the effectiveness of our approach.
Conclusion
We discussed how to build a query translation model using GPT-3’s few-shot learning and then presented how to improve its translation performance using GPT-3’s fine-tuning with data augmentation. By leveraging AI (Artificial Intelligence) technologies, an AI-assisted SOC (Security Operations Center) will understand user intent and recommend courses of action in the near future. Our AI-powered query interface is one of the steps toward our AI-assisted SOC vision.