Introduction
At Sophos we take a neural network approach to detecting previously unseen malicious and derogatory URLs. We use a combination of 7 different machine learning models on this problem, most of which look at web page content, but one of which, which we’ll examine today, looks solely at URL character strings to find evidence of maliciousness. The model we use is a convolutional neural network we created, which you can read about here: https://arxiv.org/pdf/1702.08568.pdf. The linked paper gives the math behind the approach, but how does it work in practice? What indicators of maliciousness does the neural network find in individual malicious URLs that it detects? In this post we’ll have a look at a few malicious URL detections and use a method called LIME (https://arxiv.org/pdf/1602.04938.pdf) to answer these questions.
To find malicious URLs for this blog post, I grabbed a production-trained URL model that was trained solely on URLs that were seen for the first time before Oct 5th 2020. Then I selected URLs from our database that were seen for the first time after Oct 5th 2020 (i.e., our model never saw that URL during training), which, at the time of scanning, our standard Sophos systems did not block, but later did. I took a small random sample of these, applied our model, and used LIME to help figure out how our model did manage to correctly identify malicious URLs Sophos had never seen before, and how it would have protected our customers even when our more traditional, non-ML systems might have missed them the first time. LIME is a tool to help figure out why a black-box model (like a deep neural network) scored an input sample in the way it did.
Example 1
hXXp://firstleadforex.co.cc
Here’s a URL that Sophos at least (as well as a few other vendors on VirusTotal) classifies as malicious. This is a live screenshot of the site, courtesy of urlscan.io. The “.co.cc” might look a little suspicious, and it’s a HTTP (not HTTPS) URL, but other than that I don’t notice anything particularly suspicious about this URL.
The model gives it a score of about .998 – pretty darn malicious. Scores get higher than that (.9999), but the model is very confident this is a bad URL.
Initially, I had no idea why the model was so confident. There were zero URLs from the firstleadforex domain during the time the model was trained. LIME confirmed that the model wasn’t particularly worried about the ‘firstleadforex’ token, but was worried about the ‘co.cc’ ending.

And indeed, looking at our database, there are a lot of URLs ending with “.cc/”, “co.cc/”, and about half and 97% of these respectively are classified as malicious.
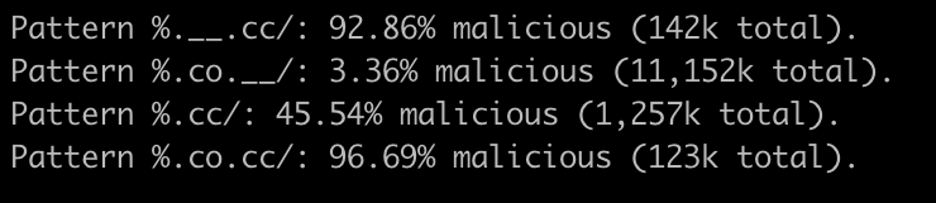
So it makes sense that the model would have a high score, although .998 seems surprisingly high to me, still. Likely there are other patterns that the model is keying into that are hard to understand without analyzing massive amounts of malicious and benign URLs.
Example 2
hXXp://cdd.net.ua/apothecary/shipping.php?osCsid=e90f855165e51ddaa7cec71839de9fe2
Here’s an interesting one. Our model gave this URL an extremely high score: 0.999977. Needless to say, a huge number of similar URLs (like hXXp://cdd.net.ua/apothecary/*) have been seen in the past that were also malicious. However, it seems like it wasn’t similar enough for existing Sophos signatures to auto-block it. When this URL was first seen on December 6th, 2020, Sophos classified it as ‘low risk’. Eight hours later, Sophos corrected the mistake and moved the URL to high risk. What’s cool is, even though our model was only trained on URLs first seen before Octobers 5th 2020, and it had never seen this one before, the model was still sure enough to block this URL immediately.


Example 3
HXXP://70.39.251.94/cnrtppdm8n/ggcd/kk2o8mi
This is a URL whose broad pattern (some IP, followed by multiple sections of randomly generated sequences) is common to malicious URLs. This is the kind of thing that can be a little harder to detect through just signatures, but a neural network does a good job of figuring out the difference between ‘random scramble of numbers’ versus ‘actual words in a URL’. This URL was seen for the first time on Nov 11th, 2020, and was initially unclassified, and later determined to be malicious. Our model gave it a score of 0.9998 – very high, despite never seeing it before.

According to LIME, our model disliked just about everything in this URL. If you remove any single chunk of this URL, it becomes less malicious looking, according to our model. Why?
I looked in our database and expected to find a lot of malicious URLs from before Oct 6th from the same IP. But, I didn’t. In fact, before Oct 6th, our database had only seen three URLs coming from that IP: one classified as malicious, one unknown, and one classified as benign. Not exactly damning evidence. Same story with similar IPs, like ones starting with “70.39”: there wasn’t a huge prevalence of malware, so how does our model know it’s malicious? Well, first I got worried we had some massive bug in the way we record the maximum first-seen-time in our model’s training data (following a good data science rule: if something looks really interesting or impressive, it’s probably a bug). But, no bug. Instead, it looks like the model is keying entirely into 1) the IP itself looks somewhat suspicious (first off, it’s not a named domain, and second, about a third of URLs starting with an IP of 70.* are malicious in our database, which is above average), and 2) the text chunks appear to be randomly generated keys, which is common in malicious URLs.
Let’s play around with this URL a bit. What happens if we start messing with the URL, even more than LIME does?
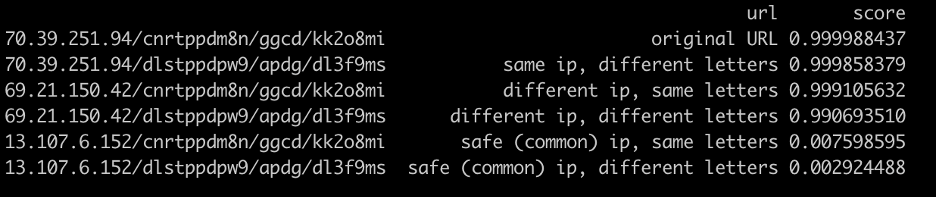
If we maintain the pattern of the URL, though change both the IP and the letters that come after, the score remains high. And if we change the IP to a common, trusted IP (I got 13.107.6.152 is a Microsoft Outlook IP). And if we start removing or adding things that change the pattern, the score also drops:

These are pretty large changes for just a few letters. Is that bad? Not inherently. The model seems to be understanding that “.html” is no longer a random key (which is a sign of maliciousness), so postfixes drop down the scores by a lot (save for .exe, because lots of malware is transferred through .exe files). And because the model hasn’t seen a lot of malicious URLs like that, the scores drop.
At the end of the day, our trust in the model’s prediction (given these changes) comes down to if we think our training and validation distributions are a fair representation of future production data. Our model is not overfitting to this URL, because it’s never seen it before! But that doesn’t mean our model isn’t overfitting to its training dataset. This is why it’s important to always monitor time-split, production validation statistics when developing models (not just time-split holdout sets from whatever parent distribution we use for training). Time will tell if our model is overfitting, but at least for now, it does a great job at identifying never before seen malicious URLs, that other existing systems miss.